
## Make robotics and industrial data queryable
ReductStore is high-performance, time-indexed object storage for robotics and industrial IoT.
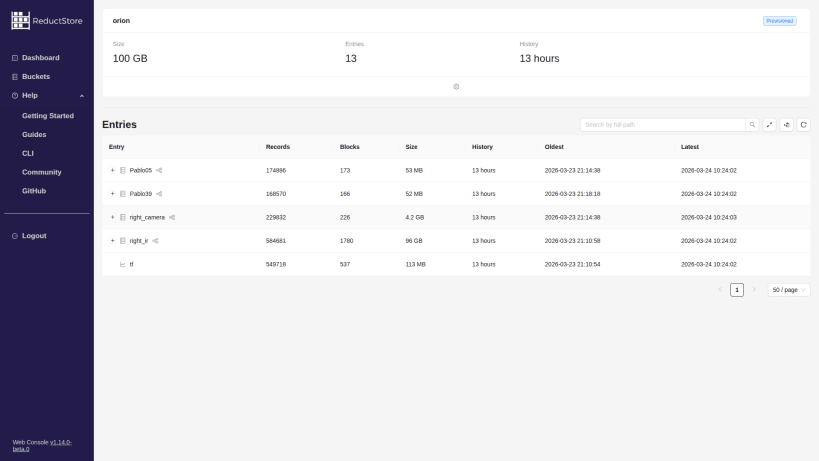
Store terabytes of images, video, sensor readings, logs, files, and ROS bags in their native binary formats. Every record is organized by timestamp and can be enriched with labels, so you can retrieve exactly the data you need by time range and operational context.
Instead of combining a time-series database, generic object storage, metadata indexes, and custom retention jobs, ReductStore provides one system for ingesting, organizing, retaining, and querying multimodal time-series data.
You are about to open
Do you wish to proceed?
Thank you for your report. Information you provided will help us investigate further.
There was an error while sending your report. Please try again later.
Snaps are applications packaged with all their dependencies to run on all popular Linux distributions from a single build. They update automatically and roll back gracefully.
Snaps are discoverable and installable from the Snap Store, an app store with an audience of millions.
On Debian 9 (Stretch) and newer, snap can be installed directly from the command line:
sudo apt update
sudo apt install snapd
After this, install the snapd snap in order to get the latest snapd:
sudo snap install snapd
To install ReductStore, simply use the following command:
sudo snap install reductstore
Browse and find snaps from the convenience of your desktop using the snap store snap.

Interested to find out more about snaps? Want to publish your own application? Visit snapcraft.io now.
