
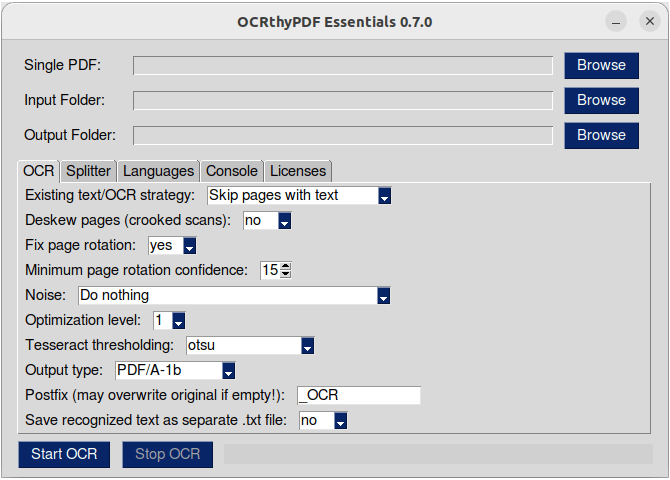
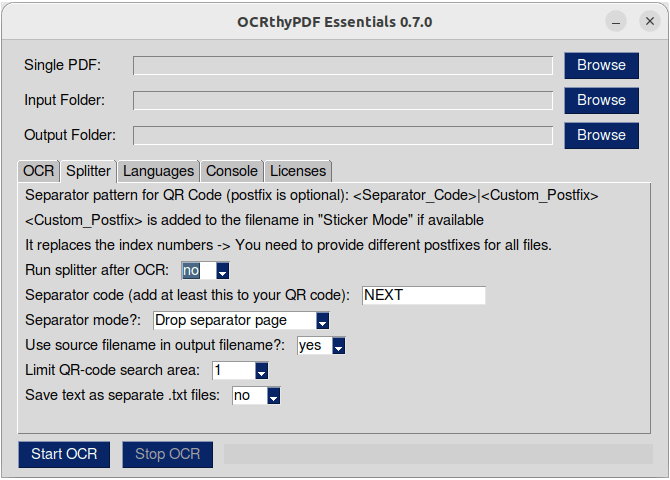
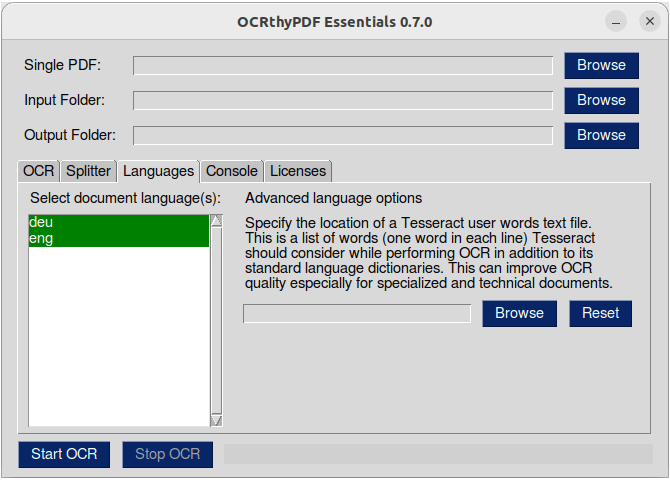

This is a user interface for the command line tool OCRmyPDF.
It's main purpose is to provide users that are not used to command line tools access to OCRmyPDF's basic features.
You can use it to make PDF files that contain images with text (e. g. after scanning) searchable by adding an invisible text layer.
It supports more than 100 languages "out-of-the-box" (all languages that are installed with tesseract).
The splitter function extends the text recognition provided by OCRmyPDF. It adds the feature to separate scanned documents at separator pages - defined by a QR code - before text recognition. A QR code can mark a separator-only page that will be discarded. Alternatively, in Sticker Mode, the QR code can mark the first page of a new document and is retained.
Make sure to switch on "Read/write on removable storage devices" in the permission settings!
If you like the program, please write a review in the store.
In case of an issue, please report the issue here:
You are about to open
Do you wish to proceed?
Thank you for your report. Information you provided will help us investigate further.
There was an error while sending your report. Please try again later.
Snaps are applications packaged with all their dependencies to run on all popular Linux distributions from a single build. They update automatically and roll back gracefully.
Snaps are discoverable and installable from the Snap Store, an app store with an audience of millions.
Snapd can be installed from Manjaro’s Add/Remove Software application (Pamac), found in the launch menu. From the application, search for snapd, select the result, and click Apply.
Alternatively, snapd can be installed from the command line:
sudo pacman -S snapd
Once installed, the systemd unit that manages the main snap communication socket needs to be enabled:
sudo systemctl enable --now snapd.socket
To enable classic snap support, enter the following to create a symbolic link between /var/lib/snapd/snap and /snap:
sudo ln -s /var/lib/snapd/snap /snap
Either log out and back in again, or restart your system, to ensure snap’s paths are updated correctly.
To install OCRthyPDF Essentials, simply use the following command:
sudo snap install ocrthypdf
Browse and find snaps from the convenience of your desktop using the snap store snap.

Interested to find out more about snaps? Want to publish your own application? Visit snapcraft.io now.
