
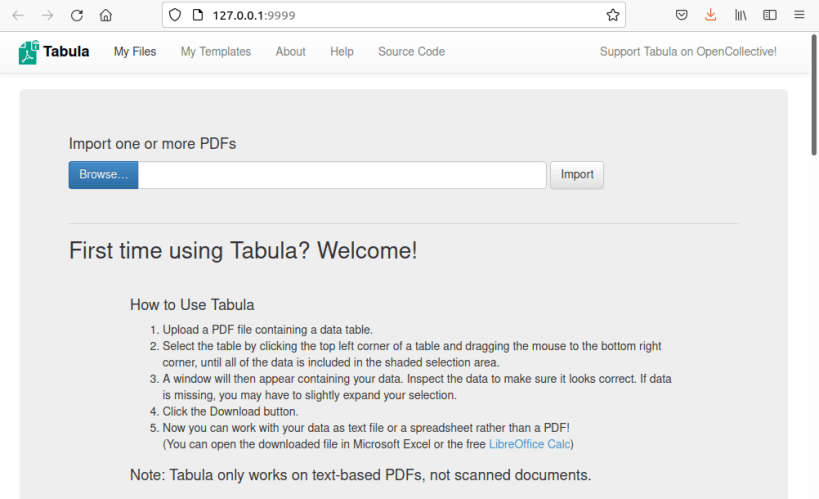

If you’ve ever tried to do anything with data provided to you in PDFs, you know how painful this is — you can’t easily copy-and-paste rows of data out of PDF files. Tabula allows you to extract that data in CSV format, through a simple web interface.
Caveat: Tabula only works on text-based PDFs, not scanned (purely image based) documents. If you can click-and-drag to select text in your table in a PDF viewer (even if the output is disorganized trash), then your PDF is text-based and Tabula should work.
Security Concerns?: Tabula is designed with security in mind. Your PDF and the extracted data never touch the net -- when you use Tabula on your local machine, as long as your browser's URL bar says "localhost" or "127.0.0.1", all processing takes place on your local machine. Even external version checks and the anonymous stats counter have been disabled in the snap.
If you start the program by clicking on it's icon this snap starts a local web server and then automatically opens a browser window. Close the terminal window to stop the server.
To learn how to use Tabula in the best way, I recommend Alastair Otter's tutorials on YouTube: https://youtu.be/IEusn9HB1sc
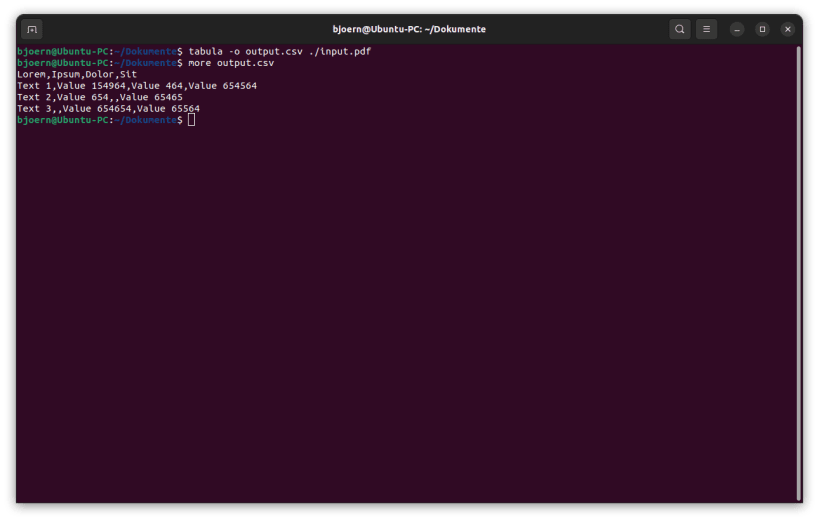
In addition to the Tabula server this snap brings you "Tabula-Java" - the command line version of Tabula. Type tabula --help in your terminal to learn about the available parameters.
It is a community snap without support by Tabula's authors.
You are about to open
Do you wish to proceed?
Thank you for your report. Information you provided will help us investigate further.
There was an error while sending your report. Please try again later.
Snaps are applications packaged with all their dependencies to run on all popular Linux distributions from a single build. They update automatically and roll back gracefully.
Snaps are discoverable and installable from the Snap Store, an app store with an audience of millions.
If you’re running Kubuntu 16.04 LTS (Xenial Xerus) or later, including Kubuntu 18.04 LTS (Bionic Beaver) and Kubuntu 18.10 (Cosmic Cuttlefish), you don’t need to do anything. Snap is already installed and ready to go.
Versions of Kubuntu between 14.04 LTS (Trusty Tahr) and 15.10 (Wily Werewolf) don’t include snap by default, but snap can be installed from the command line as follows:
sudo apt update
sudo apt install snapd
To install Tabula, simply use the following command:
sudo snap install tabula
Browse and find snaps from the convenience of your desktop using the snap store snap.

Interested to find out more about snaps? Want to publish your own application? Visit snapcraft.io now.
