
Install latest/stable of Simple-Text-Extractor
Ubuntu 16.04 or later?
Make sure snap support is enabled in your Desktop store.
Install using the command line
sudo snap install simple-text-extractorDon't have snapd? Get set up for snaps.
You are about to open
Do you wish to proceed?
Thank you for your report. Information you provided will help us investigate further.
There was an error while sending your report. Please try again later.
Generate an embeddable card to be shared on external websites.
Simple Text Extractor is a high-performance, 100% offline local document workstation. Going far beyond basic text extraction, it seamlessly combines industrial-grade OCR, smart PDF merging, and a brand-new Secure Viewer to let you process, inspect, and manage your sensitive documents with absolute privacy.
The application comes bundled with its own Tesseract OCR engine and Ghostscript, specifically optimized to provide a turnkey experience on Linux without any complex dependencies.
What's New in v1.4: "Secure Viewer & Enhanced Privacy Edition"
Integrated Secure Viewer: A natively isolated (sandboxed) viewer to inspect your PDFs and images (PNG, JPG, TIFF, BMP) without relying on unsecure third-party apps.
Zero-Persistence (100% RAM): Documents are loaded directly into memory. No caches or residual technical traces are left on your disk upon closing.
Pre & Post Inspection: View your files before processing, or instantly verify OCR results right from the dashboard.
Advanced Tools: Features instant keyword search, dynamic zooming, secure direct printing, and a one-click "Copy All Text" button to grab your OCRed data instantly.
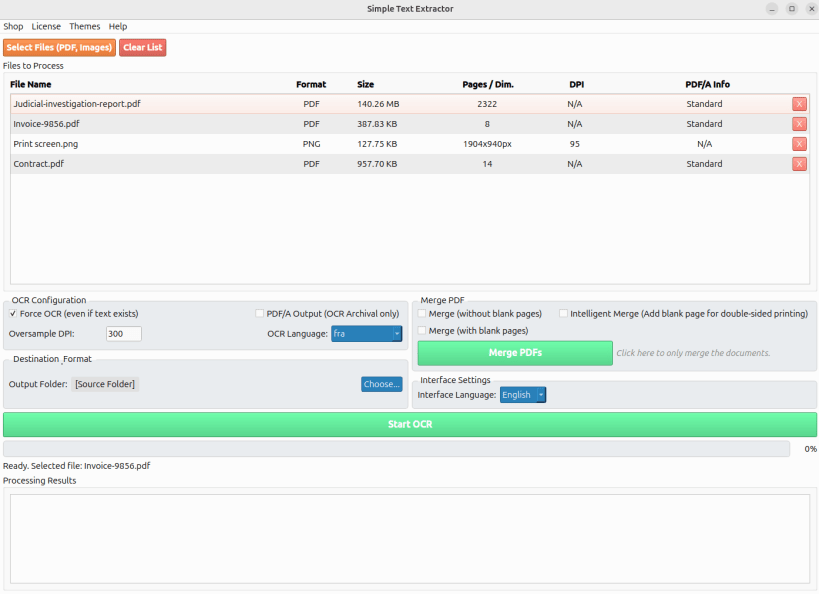
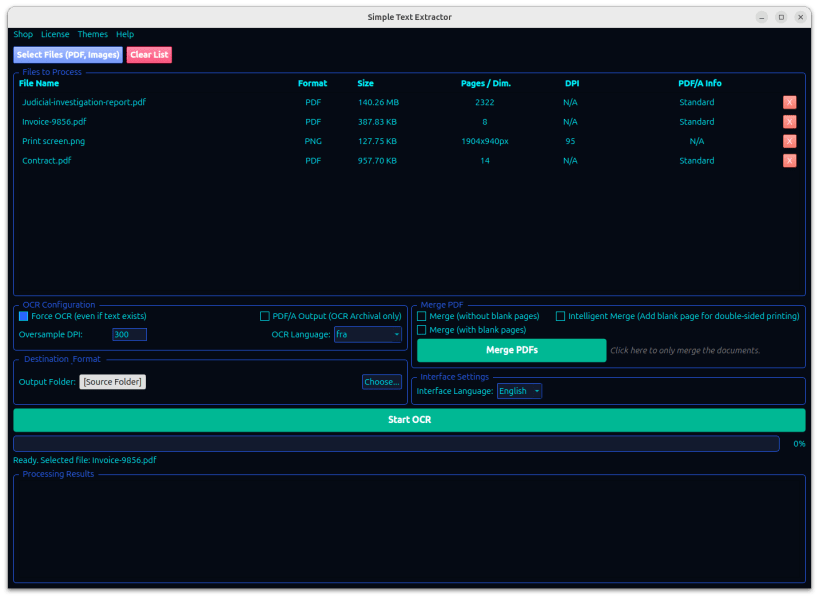
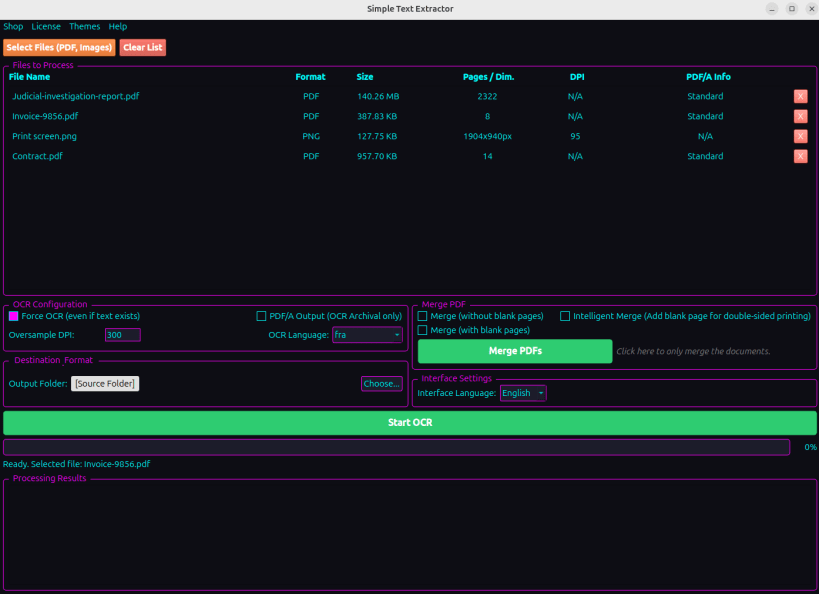
Customizable Visual Themes: A new interface allowing you to switch effortlessly between five tailored moods: Neon, Dark, Arcade, Cyber-electric, or System Default.
Log Injection Mitigation (CWE-117): Strict filtering of third-party process streams preventing any malicious metadata from falsifying system logs.
Key Features:
100% Offline & Private: Your documents never leave your computer. Ideal for legal, medical, or fiscal archives.
Smart PDF Merger: Combine multiple documents with three specialized modes: All Pages (standard merge), No Blanks (ink-coverage analysis), and Intelligent Duplex (parity management for double-sided printing).
Professional Archiving (PDF/A): Generate PDF/A-1b files for long-term preservation using the integrated Ghostscript engine.
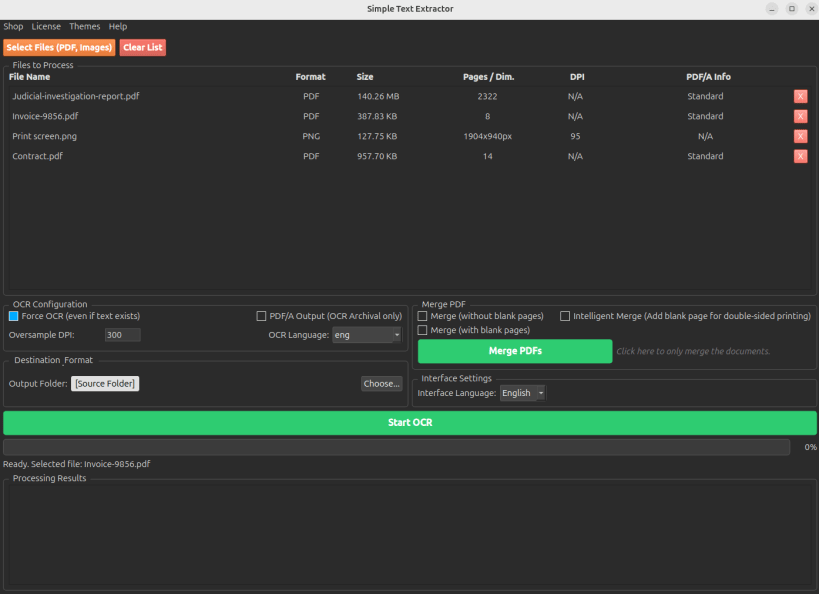
Expanded OCR Language Pack: Now includes 17+ native languages (French, English, German, Dutch, Italian, Spanish, Portuguese, Chinese, Arabic, Japanese, Russian, Turkish, Vietnamese, Norwegian, Swedish, Danish, and Greek).
Batch Processing: Process multiple PDFs or images in one click.
Zero-Freeze UI: Completely asynchronous architecture ensuring the interface remains responsive even during heavy processing.
Metadata Analysis: Instant view of DPI, page count, and PDF/A status before processing.
Hardened Robustness: Native protection against "Decompression Bombs" (malicious high-pixel images) and command injection.
Log Anonymization (CWE-209): All system logs are now automatically scrubbed to mask usernames and personal file paths, ensuring zero information leakage.
Atomic File Handling (CWE-377): Secure temporary file creation in isolated "bunkers" with restricted permissions and atomic deletion to prevent data persistence.
Memory-Optimized Engine: Tuned ThreadPoolExecutor logic avoids memory saturation (OOM), allowing the processing of massive files (2300+ pages) without slowing down your OS.
How to Use:
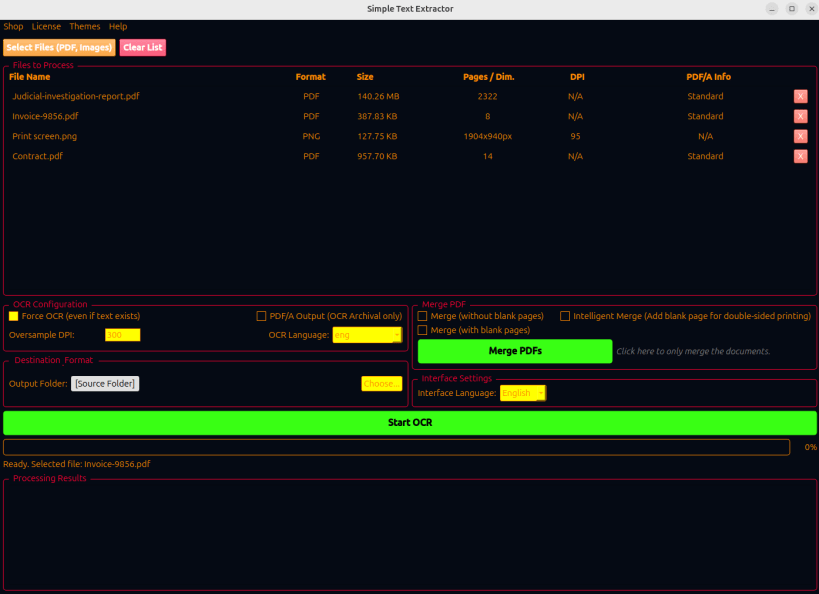
Add Files: Drag and drop your PDFs or images into the window.
Configure: Choose your OCR language or select a PDF merging mode.
Process: Click "Start OCR" or "Merge PDFs" and follow the real-time progress.
Inspect securely: Click the eye icon (👁️) or right-click any processed file to open it in the Secure Viewer. Search, copy text, or print directly!
💡 Tip: Using Wayland? If Drag & Drop doesn't work, please use the "Add Files" button or switch to an X11 session.
⚠️ IMPORTANT: Accessing External Drives (USB / Secondary Drives)
By default, the strict security confinement prevents the app from reading your USB sticks or external hard drives. If your files are stored on removable media, you must grant access by running this command once in your terminal:
COMMAND: sudo snap connect simple-text-extractor:removable-media
Choose your Linux distribution to get detailed installation instructions. If yours is not shown, get more details on the installing snapd documentation.
